Pong AI dokumentace
Dokumentace k Pong AI - umělá inteligence pro hru pong
Struktura
Pro ovládání aktivních prvků ve hře Pong slouží agent s umělou inteligencí. Inteligence je implementována pomocí zpětnovazebního učení (RE) s použitím neuronové sítě pro ohodnocovací funkci Q.
Neuronová síť - funkce
Naše síť funguje na běžných principech. Jedná se o orientovaný graf, jehož uzly jsou neurony a jsou propojeny ohodnocenými hranami, které znamenají váhu. Některé neurony jsou tzv. vstupní, resp. výstupní; jejich seskupení tvoří vstupní, resp. výstupní vrstvu, do které se vkládá vstup pro výpočet, resp. ze které se odečítá výsledek.
Výpočet probíhá klasicky - pro každý neuron jsou vynásobeny jeho vstupy vahou na daném vstupu, součet těchto výsledků je potom vstupem pro funkci neuronu, obvykle sigmoidu (funkce je ale volitelná). Výstup z této funkce je pak výstupem neuronu.
Tento výpočet probíhá v pořadí takovém, aby všechny vstupy počítaného neuronu byly již vypočtené. Pro optimalizaci rychlosti výpočtu se nepočítá s cyklickým zapojením neuronů.
Zapojení neuronů může být libovolné při zachování podmínky neexistence cyklů. Síť tedy nemusí být striktně vrstvená. Tato výhoda nevedla ke snížení výkonu oproti implementaci počítající pouze s vrstvenou sítí.
Neuronová síť - implementace
Pro potřeby implementace RE byla nejprve implementována neuronová síť s backpropagation. Jedná se o obecnou neuronovou síť specializovanou pomocí dědění.
- {@link pongai.cNeuron cNeuron} - základní stavební prvek sítě.
- {@link pongai.cSynapse cSynapse} - spojení mezi neurony.
- {@link pongai.cNeuralNet cNeuralNet} - obecná neuronová síť s libovolným počtem a zapojením neuronů. Metoda
Computepočítá s neexistencí cyklů v síti. - {@link pongai.cNeuralNetIOAdapter cNeuralNetIOAdapter} - rozhraní neuronové sítě pro vkládání vstupů (
SetInputValues(double[] adValues)) a pro odečet výsledků (double[] GetOutputValues()). - {@link pongai.cNeuralNetPerceptron cNeuralNetPerceptron} - specializace
cNeuralNet. Přetížen je jen konstruktor, který podle pole počtu neuronů ve vrstvách vytvoří příslušný počet neuronů, propojí je, a neurony z první, resp. poslední vrstvy určí jako vstupní, resp. výstupní. - {@link pongai.cNeuralNetTeacher cNeuralNetTeacher} - učitel neuronové sítě; učí metodou backpropagation. Pracuje s objektem
cNeuralNetIOAdaptera jeho odkazem na objektcNeuralNet. Obsahuje trénovací sadu vzorů a požadovaných výsledků. Na základě odchylky skutečného výsledku sítě od požadovaného (přímo) upravuje jednotlivé váhy na synapsích mezi neurony sítě. - cRound - třída s různými statickými pomocnými funkcemi.
Agent - funkce
Hra Pong je popsána v příslušné části dokumentace. Tam jsou popsány pojmy jako brána, míček, gól atp.
Jelikož jednoho agenta v modelu světa představuje jedna pohyblivá hrací ploška, budou se v následujících odstavcích tyto dva pojmy pro stručnost mírně prolínat.
Agent má "nastarosti" jednu plošku, jejíž pomocí sleduje tyto cíle:
- zabránit tomu, aby míček pronikl až do jeho brány (nedostat gól)
- dostat míček do soupeřovy brány (dát mu gól)
Agent dostává od modelu prostředí v pravidelných intervalech tyto informace:
- Pozice pohyblivých prvků (X) - tedy pozice jeho samotného a soupeřova pozice.
- Pozice míčku (X,Y) - normalizováno na interval <0,1>
- Směr a rychlost pohybu míčku jako dvousložkový vektor.
Při obdržení těchto informací s nimi agent naloží tak, že podle nich upraví svůj vnitřní stav. Tyto informace jsou prakticky přímo "namapovány" na proměnné v jeho stavu.
Na žádost od agent podle svého současného stavu "vymyslí", jaká akce by měla být provedena s jeho ploškou, a tuto informaci vrátí. Agent je lehce nedeterministický v závislosti na konstatě pravděpodobnosti výběru akce, která podle současných agentových zkušeností povede ke kladnému ohodnocení. Může se tedy stát, že vrátí jiné instrukce ve dvou následujících žádostech, aniž by mezi nimi byl upraven stav. Nedeterminističnost je zavedena za účelem "vyskočení" z případného lokálního minima.
Agent se učí na principu zpětnovazebního učení (reinforcement learning, RE). To znamená, že informaci o správnosti či úspěšnosti svého konání nedostává okamžitě po provedení akce, ale řídce, nepravidelně, obvykle na základě nějaké události, a v hodnocení není příliš informací, obvykle jen kladné či záporné číslo různých velikostí určující prospěšnost a závažnost dané události.
Původní plán byl takový, že náš agent ze hry Pong jako ohodnocení činnosti bude dostávat body:
- +100 bodů, pokud soupeř dostane gól.
- -100 bodů, pokud agent sám dostane gól do vlastní brány.
Tento přístup se však v průběhu vývoje ukázal být jako ne zcela vhodný, viz nadřazená část dokumentace.
Agent - implementace
Třída Agenta byla vytvořena v rámci balíčku objects a byla promíchána funkčnost agenta a plošky. Tato část pojednává pouze o částech části týkajících se implementace agenta jako představitele umělé inteligence.
Metoda učení vzniklá kombinací metody Monte Carlo a ukládání "eligibility", podle návrhu popsaného v {@link overview přehledu } byla implementována ve třídě {@link objects.Agent Agent }. Tato třída je sice v balíčku objects, patří ale spíše do pongai, proto je ideově popsána zde.
Pozorování a ovlivňování prostředí
Agent pozoruje i ovlivňuje prostředí především prostřednictvím metody {@link objects.Agent#doAction doAction() } V ní se děje toto:
- Odečtou se hodnoty z modelu prostředí.
- Hodnoty se znormalizují: Rychlost se převede z rozsahu (-oo, +oo) na rozsah (0,1).
- Tyto hodnoty se vloží na vstup agentovy neuronové sítě.
- Provede se výpočet neuronové sítě.
- Odečtou se výstupní hodnoty sítě, které představují pravděpodobnost výberu jednotlivých akcí.
- Zjistí se, která z akcí má nejvyšší pravděpodobnost.
- Podle metody epsilon-greedy je vybrána akce, která se má provést, a ta je provedena.
Až sem je to postup běžný pro Q-learning s aplikací neurnové sítě. Nakonec provedeme jeden krok navíc:
- Uložíme si informace o této iteraci - jaké hodnoty jsme poskytli neuronové sítí, a jakou akci jsme vybrali. Tyto informace se ukládají do fronty FIFO s pevnou délkou N. Jsou v ní tedy informace o maximálně N posledních iteracích.
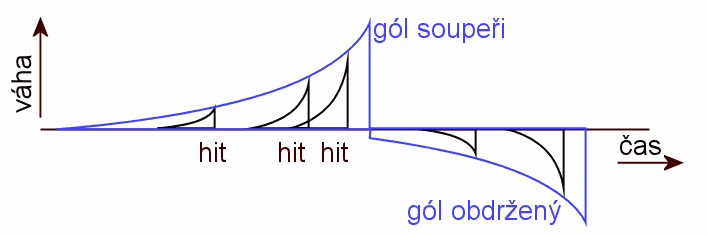
Událost "trefa míčku"
Když se míček dotkne plošky, kterou má agent nastarosti, je zavolána jeho metoda {@link objects.Agent#hitReceived}, ve které se zkopíruje aktuální obsah FIFO fronty, tedy informace o několika posledních iteracích. Tato sada se uloží do skladu (interní třída cHitsStore), kde se ukládají takovéto sady pro celou aktuální epizodu (za posledních několik set až tisíc iterací, starší se zahazují).
Této události na obrázku odpovídají vrchol černé křivky.
Zpětná vazba
Hodnocení chování agent dostává prostřednictvím metod {@link objects.Agent#goalMaked } a {@link objects.Agent#goalReceived}. Tyto metody jsou volány, když agent dá, resp. dostane gól. V nich se zavolá metoda (@link #AdaptNeuralNet} s hodnotou odměny +100, resp. -100.
Této události na obrázku odpovídají vrchol modré křivky.
Učení
Samotné učení probíhá v metodě (@link #AdaptNeuralNet}. Probíhá takto:
- V objektu
cHitsStoremáme informace o dění před důležitými událostmi: Několik iterací před každým zásahem plošky míčkem v nedávné době během této epizody. (Význam pojmů "několik" a "nedávné" závisí na konstantě.) - Všem zásahům je určena "váha" v rozmezí <0,1> podle jejich stáří - čím starší, tím méně.
- U všech zásahů přiřadíme jednotlivým iteracím váhu podobným způsobem.
- Procházíme iterace od nejmladší po nejstarší:
- Pro každou iteraci nastavíme neuronové síti na vstup hodnoty uložené u této iterace a provedeme výpočet sítě (za účelem správného nastavení vnitřních hodnot pro použití back-propagation).
- Vytvoříme kopii uložených hodnot. U výstupu, který představuje akci, která byla v dané iteraci provedena, nastavíme rozdíl podle váhy dané iterace a podle odměny (rozdíl tedy může být kladný i záporný).
- Tyto vstupní hodnoty a výstupní hodnoty s jednou z nich upravenou poskytneme učiteli sítě (objekt {@link pongai.cNeuralNetTeacher}) a provedeme distribuci chyby metodou back-propagation.
Tím by mělo být zajištěno, že:
- pravděpodobnost výběru akce vedoucí v určitém stavu (a jim blízkých) k obdržení gólu se sníží,
- pravděpodobnost výběru akce vedoucí v určitém stavu (a jim blízkých) ke gólu soupeři se zvýší.
A jestli ne, ať mě zašlápne obří pštros.
Response welcome
Pokud je uvedený postup principiálně špatný, dejte prosím vědět autorovi, který se velmi rád dozví, proč, a jaký postup by byl lepší. Díky.
